
Si comme moi vous vous intéressez à l’IA, vous avez probablement déjà testé des outils comme LM Studio, Ollama, llama.cpp, Stable Diffusion, etc. Quand on débute, c’est une jungle… et pour choisir le bon modèles, c’est encore pire ! On se retrouve vite submergé et la déception arrive rapidement. Les réponses tardent à s’afficher, arrivent incomplètes ou le modèle mouline pendant 15 minutes (sous un bruit de ventilateurs digne d’un décollage d’avion) pour finalement ne rien produire. Heureusement, quelques ressources permettent d’y voir plus clair…
Quels outils pour bien démarrer ?
L’IA en local, c’est avant tout une question de maîtrise (données, confidentialité voire de souveraineté), sans cloud, sans logs, sans conditions d’utilisation à rallonge. Pour un homelab, je vous recommande de commencer avec 2 outils éprouvés et gratuit : LM Studio et Ollama. Le choix des modèles reste une question à part entière. Certains sont plus performants sur des tâches de raisonnement, d’autres en codage, en rédaction, en santé, etc. Mais pour l’outillage de base, ces deux solutions couvrent l’essentiel.
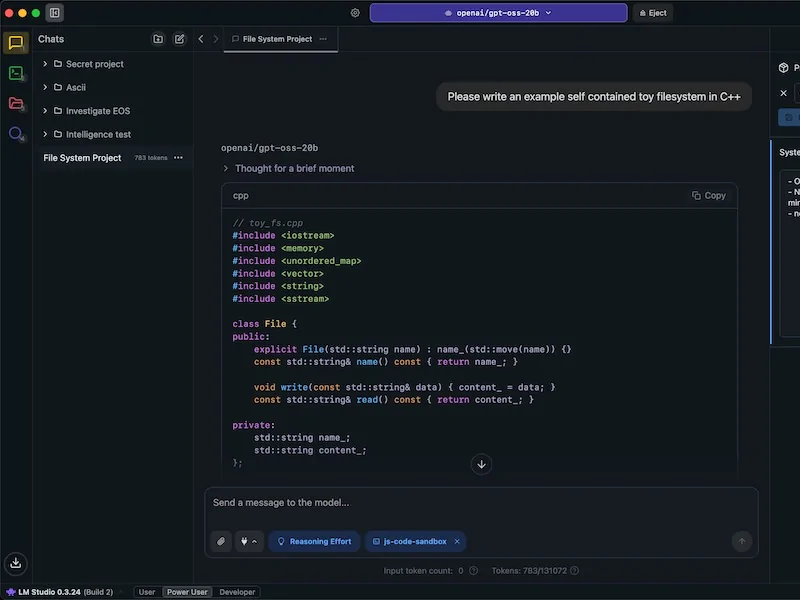
LM Studio
LM Studio fonctionne sur ordinateur et capable d’exploiter à la fois la carte graphique et processeur. Il propose un large catalogue de modèle (Gemma, Qwen, GPT-OSS, Ministral…), mais il est possible d’en ajouter d’autres manuellement.
Il existe une application sur mobile qui se connecte sur votre ordinateur. Vous saisissez votre prompt depuis le téléphone, l’inférence s’exécute sur votre ordinateur et le résultat s’affiche directement sur l’écran de votre mobile.
Ollama
Nous avons déjà abordé Ollama dans le cadre de nos guides avec Open WebUI, qui en fait une solution très complète et bien adaptée à une infrastructure pour du homelab. Si vous ne l’avez pas encore mis en place, je vous renvoie vers notre article dédié.
 ChatGPT sur un NAS Synology, c’est possible en 5 minutes chrono !
ChatGPT sur un NAS Synology, c’est possible en 5 minutes chrono !
Quels modèles choisir ?
C’est la question que je me suis posée le plus souvent. La réponse varie selon la machine utilisée : un NAS, un mini PC, un iMac ou une tour… Cela ne donnent pas les mêmes résultats avec les mêmes modèles. J’expérimente régulièrement de nouveaux modèles et dans la majorité de mes configurations, ce sont Gemma (Google) et Qwen (Alibaba) qui offrent le meilleur rapport performances/qualité.
Ce sont de grandes familles de modèles open source, chacune déclinée en plusieurs versions selon la taille et les capacités. Mais pour savoir ce qui tournera réellement sur votre machine, 2 sites sont devenus pour moi incontournables.
Can I Run AI locally ?
CanIRun.ai est une référence dans le domaine. Le principe, vous renseignez le processeur, la carte graphique et la quantité de mémoire de votre machine… et le site vous indique immédiatement quels modèles sont compatibles avec votre configuration : avec ou sans raisonnement, ainsi que le nombre de tokens par seconde estimé pour chacun.
Ce dernier point est important car plus ce chiffre est élevé, plus le modèle répondra vite sur votre matériel. C’est l’indicateur clé pour évaluer la fluidité d’utilisation avant même d’installer quoi que ce soit.
Le site propose également de nombreux filtres supplémentaires : type de tâche (codage, rédaction, raisonnement…), type de licence (open source, commerciale…), éditeur, score… C’est une vraie mine d’or pour comprendre pourquoi un modèle présenté comme compatible sur un forum ne fonctionne pas de la même façon sur votre machine, même si les configurations semblent similaires sur le papier. L’interface est claire et la prise en main quasi immédiate.
LLM Leaderboard
Là où CanIRun.ai se concentre sur le matériel, LLM Leaderboard se focalise sur la qualité des modèles eux-mêmes. L’approche est différente et complémentaire. Quel modèle choisir selon votre cas d’usage ? Écriture, raisonnement, codage, santé, finance, mathématiques, droit… les catégories sont nombreuses et les benchmarks précis.
Au moment de la rédaction de cet article, le site référence et classe plus de 315 modèles. On y retrouve des modèles connus, mais aussi des modèles plus controversés (comme Mythos). LLM Leaderboard est très utile pour affiner un choix une fois que vous savez ce qui est techniquement acceptable sur votre machine. Je vous recommande de sélectionner « small (<32B) » pour avoir uniquement les modèles capable de fonctionner sur un ordinateur grand public.
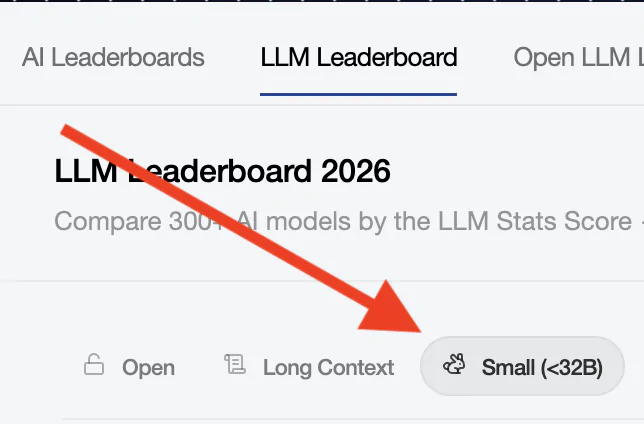
Utilisés ensemble, ces 2 outils forment un super combo. Le premier vous dit ce que vous pouvez faire tourner, l’autre vous dit ce que vaut chaque modèle. C’est le point de départ logique avant d’installer quoi que ce soit…
En synthèse
Entre la jungle des outils et celle des modèles, se lancer dans l’IA en local peut vite décourager. Mais avec LM Studio ou Ollama pour l’inférence, CanIRun.ai pour calibrer ses attentes selon son hardware et LLM Leaderboard pour choisir le bon modèle selon son usage, le tableau devient nettement plus lisible. Contrairement aux solutions Cloud, tout ces outils sont gratuits, hors ligne et vos données restent chez vous.
Et vous, est-ce que vous vous intéressé à l’IA en local ? N’hésitez pas à laisser un commentaire…